MACHINE LEARNING UND OPERATIONS RESEARCH – EINE INTERESSANTE KOMBINATION
26.01.2018 // Matthias Berlit

Machine Learning ermöglicht es Maschinen oder besser gesagt Rechnern, auf der Basis von Trainingsdaten zu lernen. Beispiele dazu gibt es etliche. Zeigt man etwa einem Machine-Learning-Algorithmus zwei Millionen Fotos von Autos und zehn Millionen Fotos mit anderen Motiven und der Programmierer sagt ihm immer, wenn es sich um das Bild eines Autos handelt, lernt er aus diesem Training die Fahrzeuge beispielsweise anhand der Form zu unterscheiden. Dieser Algorithmus wäre dann voraussichtlich recht gut in der Lage, auch ein neues, unbekanntes Foto eines Autos zu identifizieren. Denn durch Machine Learning erlangt ein Computer – ähnlich wie der Mensch – selbstständig Wissen aus Erfahrungen und kann so eigenständig eine Lösung für unbekannte Probleme finden.
Um bei solchen Trainings die Güte des Algorithmus überprüfen zu können, teilt man die Daten in Trainings- und Scoringdaten. So können beispielweise die Daten der letzten drei Jahre bis auf die letzten drei Monate als Trainingsdaten dienen. Die übrigen letzten drei Monate bilden dann die Scoringdaten. Das heißt, auf diesen Daten wird der trainierte Algorithmus angewendet, um zu überprüfen, wie zuverlässig er ist.
Beispiel Machine Learning Prozess
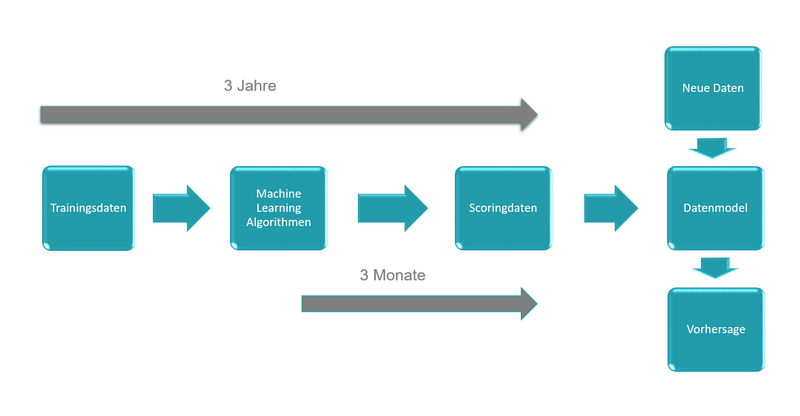
So viel zur Funktionsweise. Doch wird Machine Learning thematisiert, werden aus meiner Sicht die Optimierungsmethoden des Operations Research zu sehr vernachlässigt oder gar vergessen.
Warum ist Operations Research so wichtig?
Mit Hilfe von Machine Learning können Maschinen genau wie bei dem oben genannten Beispiel auf der Basis von Trainingsdaten geschult werden. Das Trainieren der Entscheidungen ist aber nur so gut, wie die besten Entscheidungen, die bereits getroffen wurden und in den Trainingsdaten enthalten sind. Wenn zum Beispiel ein Dispositionsalgorithmus auf Machine-Learning-Basis allein anhand der Entscheidungen von Disponenten trainiert wird, wird das finale Ergebnis nicht besser sein als die vorherigen manuellen Dispositionsentscheidungen, sie werden lediglich automatisiert ausgeführt. Denn das System erkennt bestimmte Muster und lernt anhand von den vergangenen Entscheidungen des Disponenten, also bestimmte Gesetzmäßigkeiten in bestimmten Situationen automatisch anzuwenden. Etwas provokant gesagt, wäre das ungefähr so gut, als wenn wir ein Schachprogramm anhand meiner Schachspiel-Fähigkeiten trainieren. Ein Großmeister würde dabei nicht herauskommen. Maschinelles Lernen hängt immer auch von der Wahl der richtigen Trainingsdaten ab und kann nur so gut werden, wie es die Qualität und Sinnhaftigkeit dieser Vergangenheitsdaten hergibt. Eine Ausnahme bildet hier das Reinforcement Learning, ein Teil des Maschinellen Lernens, durch das ein Programm autodidaktisch gegen sich selber trainieren kann. Das wäre im Fall der Dispositionsentscheidungen nicht einfach, aber prinzipiell denkbar. Dafür müsste dann ein Dispositionslernprogramm gegen einen Gegner antreten, der die Rolle der betrieblichen Unwägbarkeiten und Zufälle übernimmt.
Nicht nur denkbar, sondern bereits praxiserprobt sind hingegen Optimierungsverfahren des Operations Reseach. Mit Hilfe von Heuristiken oder Verfahren, wie Linearer oder ganzzahliger Programmierung, lassen sich hochkomplexe Sachverhalte mathematisch modellieren und in vielen Fällen sogar die mathematisch optimale Entscheidung treffen - in anderen Fällen immerhin sehr gute Entscheidungen nahe am Optimum.
Komplexität mit Operations Research meistern
Wenden wir uns wieder dem Beispiel des Disponenten zu. Es gibt für einen Disponenten, der 60 Fahrzeuge und 60 Aufträge disponieren soll, mathematisch gesehen 10^81 Möglichkeiten aus Fahrzeug/Auftrag-Kombinationen. Das ist eine sehr große Zahl. Zum Vergleich: Das Universum besteht aus etwa 10^80 Atomen. Die Komplexität steigt dann mit der für die Realität notwendigen Nebenbedingungen, wie in dem genannten Fall zum Beispiel Arbeitszeiten, Auftragsprioritäten, Fahrzeugkapazitäten oder Volumen der Ladungen. Recht schnell wird klar: Es ist praktisch unmöglich, dass der Disponent die eine optimale Lösung wählt. Moderne Operations-Research-Verfahren können solche Probleme allerdings in wenigen Millisekunden lösen. Kommen derartige Optimierungsverfahren zum Einsatz, zeigen sich Einsparpotenziale in einer Höhe von 10 bis 30 Prozent, je nach Größe der Anwendung und Situation (Quelle sind über 1000 Projekte dieser Art von INFORM). Die Anwendung von Machine Learning ohne Operations-Research-Verfahren hätte lediglich dazu geführt, dass die Kombination automatisch ausgeführt worden wäre, die der Disponent in der Vergangenheit bei bestimmten Bedingungen am häufigsten gewählt hat. Abhängig von der Qualität dieser Entscheidung würde das Einsparpotenzial dann ausbleiben.
Besonders hoch sind die Einsparpotenziale, wenn man Machine Learning intelligent einsetzt, um auch die dynamischen Eingangsgrößen für die Optimierungsmodelle zu erlernen, wie beispielsweise erwartete Ankunftszeiten, durchschnittliche Dauer oder zu erwartende, noch nicht gemeldete Aufträge. Diese Parameter können dann durch Machine Learning wesentlich genauer vorhergesagt werden, und das Ergebnis der Optimierung wird noch besser.
Beispielsweise können im Supply Chain Management Machine-Learning-Verfahren helfen, um die erwartete Nachfrage besser einzuschätzen, als es mit klassischen Prognosemethoden möglich ist. Solche Verfahren können dann etwa für die Absatzprognose im Lebensmitteleinzelhandel dutzende Einflussgrößen wie Wetter, Werbeaktionen oder Kalendereffekte wie Ferien und Feiertagswochen berücksichtigen.
Fazit
Anhand dieser Beispiele wird bereits deutlich, dass Machine Learning in verschiedenen Bereichen großes Potenzial hat. Den größten Optimierungseffekt und damit die höchsten Einsparpotenziale entfaltet das System in vielen Anwendungsfällen aber erst in Verbindung mit Operations-Research-Verfahren. In vielen Anwendungsfeldern bieten sich so Optimierungsmöglichkeiten, die weit über die reine Automatisierung der Entscheidungsfindung hinausgehen. Diese Potenziale sollten meiner Meinung nach nicht ungenutzt liegen bleiben. Ein Blick in die Vergangenheit mit Machine Learning lohnt sich, kombiniert mit Operations Research wird er richtig wertvoll.
Welche Potenziale sehen Sie in Machine Learning und Operations Research?
ÜBER UNSERE EXPERT:INNEN
Matthias Berlit
Matthias Berlit war zwischen 2021 und 2023 Co-CEO von INFORM. Er war seit 2001 im Unternehmen und zwischen 2010 und 2020 Geschäftsbereichsleiter Industrielogistik & Healthcare.